






















iPhone游戏引擎编写之内存管理和Maya工具(1)
作者:Simon Yeung
引言
这次我要谈论的是我的业余项目,即编写iPhone游戏引擎,这个项目从去年8月开始,由2位美工配合进行。虽然项目尚未完成,但这里我想要分享几点自己从中学到的东西。首先先来看看若干游戏截屏:(点击此处阅读文章第二、三、四部分)
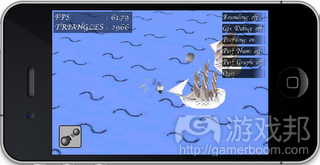
和船只战斗
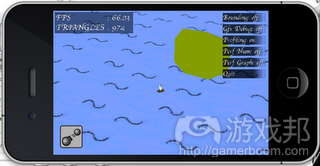
探索游戏世界
在这款游戏中,玩家通过控制船只探索游戏世界,发现新城市,同其他船只进行战斗。玩家还可以在游戏的进程中改变船只的模式。下文我将谈论我在此小型引擎中所运用的技巧,主要包括如下内容:
—内存管理
—工具(Maya插件和关卡编辑器)
—脚本处理(Lua)
—串流机制
— 声音(音效和背景音乐)
—运行调试
下面是几幅游戏截图及我目前所开发的工具:
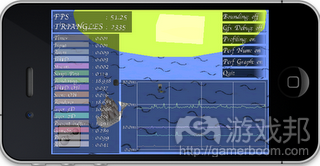
游戏轮廓
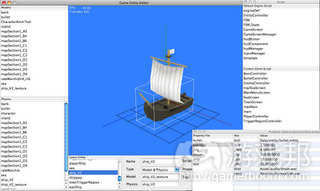
编辑器

关卡编辑器
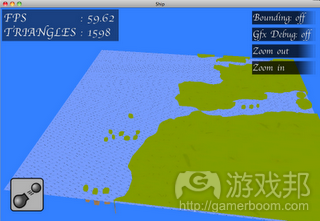
Mac版本
内存管理
在iPhone平台,内存是非常重要的资源。若处理不当,应用就会收到1-2个内存警告,然后你的应用就会被系统终止。所以我决定编写自己的内存配置器,预先分配大部分内存,这样我的应用就不会在运行时被操作系统终止,它可以选择运行或不运行。这是我首次编写内存配置器,它没像“准备、设定、分配”过程那么精细,但足以应对我的项目。
在我的小型引擎中,pool配置器主要用于分配内存,其存预先设定容量大小,从8、16、32及64字节到1048546字节不等。由于我的目标平台是iPhone,而极限容量104854字节通常只运用至若干高分辨率的纹理中,因此我的游戏的多数内存都集中在较小的容量规格。在程序运行期间,很多内存都已形成,它们被分成如下更小的模块以适应各pool规格:
")
memory Layout(from 1.bp.blogspot)
注意,大型字节模块通常位于较小内存空间,旨在实现字节对齐。而各模块则被进一步划分成同等大小的区块,以配合特定的容量配置:
")
memory 8 byte(from 3.bp.blogspot)
各模块中的内存区块保持呈现链接表模式,这样当pool配置器需要分配/归还内存时,它只需返回列表中的自由内存区块/将其添加回链接表中。各内存区块中的内存主要用于储存指示链接表下个自由内存区块的“下个指示器”,这样我们就不需要通过分配额外内存追踪链接表:
")
memory Linked List(from 1.bp.blogspot)
在进行分配时,配置器需要根据配置容量决定所要运用的pool模块。然后在此模块中,自由内存区块就会被送回,这只是模块链接表的顶部。在解除配置过程中,将内存分解成不同模块后,我们就能够把握各pool模块的边界地址,所以通过查看解除配置指示器的地址,我们就能够决定其属于哪个pool模块,然后我们就能够将内存送回模块的自由内存模块链接表。此方式的一个缺点是它无法验证解除配置指示器是否真正由用户配置,以及其是否双倍释放。想要“部分”克服此问题,我需要添加极限检查,以检验解除配置过程的输入内容。首先,我会检验输入内容的字节是否对齐,例如若解除配置指示器处于1048546字节模块中,那么指示器地址就必须和1048546字节对齐。其次,在分割内存模块的过程中,我们将获悉各内存模块存在多少内存区块,我们可以保留一个当前自由区块的数量(游戏邦注:这会随着分配和解除分配而或增或减)。若程序结束后,免费区块数量不符区块总数量,那么内存也许就被遗漏或被双倍释放。但这只能够解决部分问题。
为真正解决此问题及查看内存遗漏情况,我需要记录各个分配和解除分配操作。原本,在分配过程中,我只需要通过宏指令__FILE__,__LINE__存储返回指示器的地址及各分配操作的位置(源文件和行编号)。但这无法追踪所有内存遗漏情况,因为有些文件已被模版化,例如Bullet Physics存储库中的btAlignedAllocator.h。运用宏指令__FILE__,__LINE__只能够记录这些头文件的分配情况,这无法协助我们进行内存漏洞追踪。因此,我还通过system call backtrace()和backtrace_symbols()记录各分配过程的调用栈。然后我就能够轻松追逐所有内存遗漏情况。但记录各分配过程是个缓慢的过程,这只能够在调试版本中实现。
总之,我的内存配置器还有很多需要改善的地方,例如检验用户解除分配过程;在内存区块中添加元数据(游戏邦注:例如配置规模)。出于线程安全性考虑,我目前通过互斥量保护内存,未来我也许会转向无锁版本。尽管存在这些缺点,但这个配置器的运作情况还是颇令人满意,它让我们不会再收到iOS的内存警告,让项目不再出现内存碎片问题,同时还协助我们追踪内存漏洞情况。
Maya工具
工具在游戏制作中非常重要,特别是在合作伙伴不懂如何编写代码的情况下。在我的项目中,我的合作伙伴是两位美工,所以我得编写某些工具,将他们的模型输出到我的引擎中。输出模型有不同的方式,你可以选择解析.obj文件的格式,通过FBX SDK阅读.fbx文件,或是阅读COLLADA文件,但我选择直接从美工采用的模型包中提取内容(游戏邦注:编写Maya插件提取模型数据)。
要给输出模型编写Maya插件,我们首先得弄清数据在Maya中的存储方式。通常Maya会将多数数据存储在Directed Acyclic Graphic(DAG)。在我的项目中,我需要找出这些存储网络数据(mesh data)的DAG节点位置。我们可以按照如下方式通过迭代器MItDag访问DAG:
- MStatus status;
- MItDag dagIter( MItDag::kDepthFirst, MFn::kInvalid, &status );
- MDagPathArray meshPath; // store the DAG nodes that contains mesh
- for ( ; !dagIter.isDone(); dagIter.next())
- {
- MDagPath dagPath;
- status = dagIter.getPath( dagPath );
- if ( status )
- {
- MFnDagNode dagNode( dagPath, &status );
- // Filter out the DAG nodes that do not contain mesh
- if ( dagNode.isIntermediateObject()) continue;
- if ( !dagPath.hasFn( MFn::kMesh )) continue;
- if ( dagPath.hasFn( MFn::kTransform )) continue;
- meshPath.append(dagPath);
- }
- }
然后我们可以按照如下方式通过MFnMesh获得DAG中的网络数据:
- for(int i=0; i< meshPath.length(); ++i)
- {
- MDagPath dagPath= meshPath[i];
- MFnMesh fnMesh( dagPath );
- MPointArray meshPoints;// store the position of vertices
- fnMesh.getPoints( meshPoints, MSpace::kWorld );
- // get more mesh data such as normals, UV…
- }
想要获得更多细节内容,不妨参考《MAYA API How-To》和《Maya Exporter Factfile》。得到网络数据后,你就可以通过创建MPxFileTranslator的子类输出这些内容,取代函数writer()。
我选择编写插件而不是解析.fbx/COLLADA的另一原因和提取动画数据有关。在我的项目中,我只需要输出若干嵌入关键图框之间的简单动画数据,我想要获得美工基于Maya定义的关键图画。我尝试运用FBX SDK,但在输出动画数据时,它会将所有动画图像都聚集成关键帧。通过COLLADA所获得的结果则更加糟糕,我无法在Mac平台找到适合Maya的输出装置。而编写Maya插件能够消除所有这些问题,获得我想要的数据。我要编写一个脚本文件,帮助美工设定动画剪辑数据:
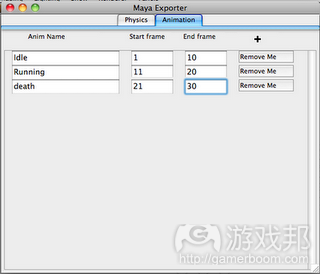
maya Anim Clip from altdevblogaday.com
输出网络数据后,我觉得在Maya中编辑触碰几何图形是个很不错的主意,所以我编写另一插件定义模型的触碰形状:
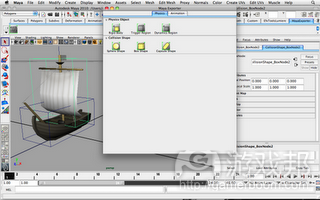
maya Physics Exporter from altdevblogaday.com
插件的运作方式和Dynamica Plugin非常相似(游戏邦注:但作者的插件只是基于球体、盒子和胶囊图形定义出简单形状)。我的插件无法在Maya中进行物理仿真,它只能够定义触碰形状。这些触碰形状只是MPxLocatorNode的子类,它推翻draw()方式,通过调用openGL渲染出内容的对应形状。
总之,直接从Maya中提取网络数据并不困难。我们可以获得所有数据,例如顶点法线、UV集合和关键帧数据,无需担心基于其他格式输出内容会导致的数据丢失情况。Maya还提供获得这些数据的便捷API,这非常容易掌握。熟悉Maya API后,我还可以编写另一插件定义触碰形状。下次当你需要输出网络数据时,你也许会考虑直接从模型包中提取相关内容,而不是解析一个文件格式。
游戏邦注:原文发布于2011年7-8月,文章叙述以当时为背景。(本文为游戏邦/gamerboom.com编译,拒绝任何不保留版权的转载,如需转载请联系:游戏邦)
Writing an iPhone Game Engine (Part 0 – Introduction)
By Simon Yeung
This time I would like to talk about my hobby project which is writing an iPhone Game Engine. This project started from August last year and works with 2 artists. Although the game is still not finished, I want to share what I have learnt so far. Let’s show some screen shots first:
In the game, the player will control a ship to explore the world, discovering new cities and fighting with other ships. The player can also change the ships when the game progress.
I will have several blog posts to talk about the techniques I used in my little engine. The up coming topics will includes:
- Memory management
- Tools (Maya plugin and level editor)
- Scripting (Lua)
- Streaming system
- Audio (OpenAL for effect sounds and Apple audio queue for BGM)
- Performance tuning
After finishing the above topics I will talk about what I have done right and what have done wrong in this project.
In my next post, I will start to talk about the Memory management in my game engine. To end up this introductory post, I would like to show you more screen shots of the game and tools I have developed so far:
Writing an iPhone Game Engine (Part 1- Memory management)
On the iPhone platform, memory is a very precious resources. If they are not handled properly, the application will receive one or two memory warning, and then your application will be killed by the OS. So I decided to write my own memory allocator to preallocate a large chunk of memory so that my game will not be killed by the OS when running, it will either start or not start. This is my first time to write a memory allocator, and it is not as sophisticated as “Ready, Set, Allocate!”, but it just works fine enough for me.
In my little engine, a pool allocator is written for memory allocation, with different pre-defined pool size ranging from 8, 16, 32, 64bytes to 1048546bytes. As my target platform is iPhone, the maximum pool size is 1048546bytes which is used only for a few high resolution textures, most of the memory is spent on the the smaller pool size. During the program starts, a large chunk of memory is created and it is divided into different smaller chunks for different pool size as follows:
Notice that the large byte chuck is located in the smaller memory address for proper byte alignment. And within each chunk, it is divided into equally sized block for each particular size allocation:
The memory blocks within each chunk are maintained as a linked list so that when the pool memory allocator need to allocate/deallocate memory, it just need to return a free memory block from the list/add it back to the linked list. The memory within each memory blocks is used to store the ‘next pointer’ for the next free memory block in the linked list so that we do not need to allocate extra memory to keep track of the linked list (this approach is learnt from Game Engine Architecture):
For each allocation, the allocator need to decided which pool chunk need to be used depends on the size of the allocation. Then within that chunk, a free memory block is returned which is just the head of the linked list within that chunk. For each deallocation, as we divide the memory into different chunk, we know the boundary address of each pool chunk, so by checking the deallocated pointer address, we can determine which pool chunk it belongs to, then we can just add the memory back to that chunk’s free memory block linked list. One drawback of this approach is it does not verify whether the deallocated pointer is actually allocated by the user nor it is double freed. To ‘partly overcome’ this problem, I added limited check to verify the input to each deallocation. First, I would check whether the input is byte aligned, for example if the deallocated pointer is within the 1048546 bytes chunk, then the pointer address must be 1048546 byte aligned. Second, as we partition the memory chunk, we know how many memory blocks is within each memory chunk, we can maintain a current free blocks number which will increase and decrease for each allocation and deallocation. When the program exits and this free block number does not match with the total number of blocks, then memory may either be leaked or double freed. But this only solve the problem partially.
To actually solve the problem and also check for memory leaks. I need to log every allocation and deallocation. Originally, for each allocation, I just store the returned pointer address and location of each allocation(which source file and line number) using the macro __FILE__, __LINE__. But this does not do well enough to track down all memory leak as some files are templated such as btAlignedAllocator.h in the bullet physics library(yes, I use bullet physics in my engine). Using the macro __FILE__, __LINE__ will only log down the allocation in these header file which does not help much for tracking memory leak. Therefore, I also log the callstack of each allocation using the system call backtrace() and backtrace_symbols()(which is available in Unix-like platform). Then I can track down all memory leak easily. However, logging every allocation is a very slow process and it is only enabled in debug build/ enabled when necessary.
In conclusion, my memory allocator still have different things to improve such as verifying the user deallocation; adding some meta-data within each memory block such as the allocation size; And for the thread safety, currently I only use a mutex to protected the memory, I may switch to a lock-free version in the future. Despite these short comings, this allocator works well enough for me as it avoid receiving memory warning from the iOS, avoiding memory fragmentation and help me track down memory leaks.
Writing an iPhone Game Engine (Part 2- Maya Tools)
Tools are very important in game production, especially when you are working with someone who cannot write code. In my project, I worked with 2 artists, so I need to write some tools to export their models to my engine. There are different choices to export the models, you can parse.obj file format(for static model only), reading .fbx file using FBX SDK, reading COLLADA files… But I choose to extract it directly from the modeling package that the artists use – Writing Maya plugin to extract the model data.
To write Maya plugin for exporting models, we should know how data are stored in Maya first. Basically, Maya stores most of its data (e.g. meshes, transformation…) in a Directed Acyclic Graphic(DAG). In my case, I just need to locate those DAG nodes that store the mesh data. We can traverse the DAG using the iterator MItDag like this:
then, we can get the mesh data in the DAG nodes using the MFnMesh like this:
For the details of getting the mesh data, you may refer to MAYA API How-To and Maya Exporter Factfile. After getting the mesh data you can export them by creating a sub-class of the MPxFileTranslator and overwrite the writer() function. You can find some useful sample code provided by Maya inside the Maya directory (/Applications/Autodesk/maya2010/devkit/plugin-ins/ on Mac platform) such as the maTranslator.cpp and objExport.cpp.
Another reason I choose to write plugin instead of parsing .fbx/COLLADA is because of extracting the animation data. In my project, I just need to export some simple animations which linear interpolates between key frames, and I would like to get the key frames defined by artists in Maya. I have tried using the FBX SDK but when exporting animation data, it bakes all the animation frames as key frames… Using COLLADA get even worse because I cannot find a good exporter for Maya on the Mac platform… So writing Maya plugin can get rid of all these problems and get the data I want. I can also write a script for artists to set the animation clip data:
After exporting the mesh data, I think it would be nice to edit the collision geometry inside Maya, so I have written another plugin to define the collision shapes of the models:
This plugin works similar to the Dynamica Plugin (In fact, I learnt a lot from it.), except mine can just define simple shapes with only spheres, boxes and capsule shapes. And my plugin cannot do physics simulation inside Maya, it is just for defining the collision shapes. Those collision shapes (sphere/box/capsule) are just sub-class of MPxLocatorNode by overriding the draw() methods with some openGL calls to render the corresponding shapes.
In conclusions, extracting mesh data directly from Maya is not that hard. We can get all the data such as vertex normals, UV sets and key frame data from Maya and do not need to worry about the data loss during export through another formats, especially animation data. Also Maya provides a convenient API to get those data and it is easy to learn. After familiar with the Maya API, I can also write another plugin to define the collision shapes. Next time when you need to export mesh data, you may consider to extract them directly from the modeling package rather than parsing a file format.(Source:altdevblogaday part 1,part 2,part 3)

")
")
")
")















 闽公网安备35020302001549号
闽公网安备35020302001549号